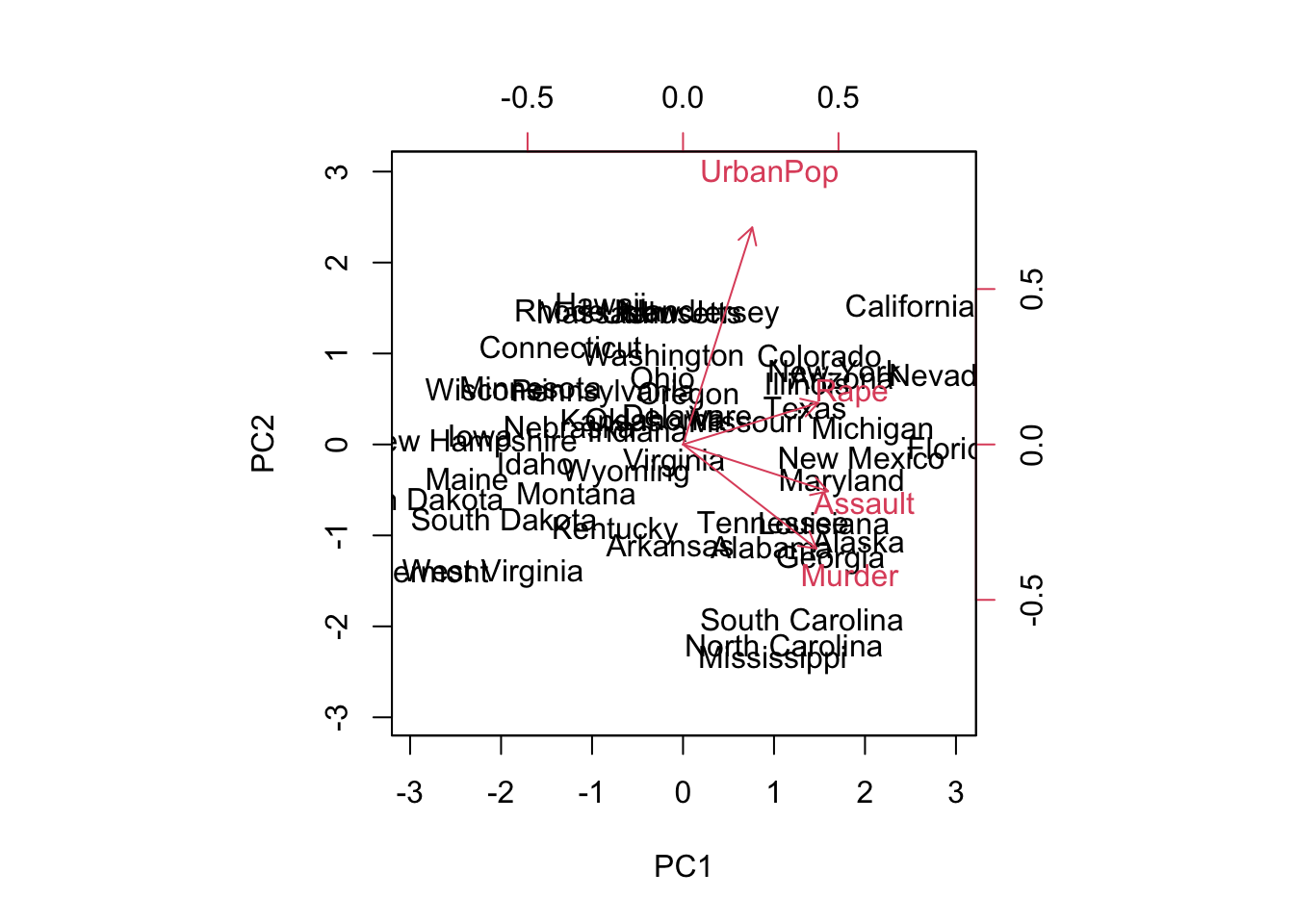
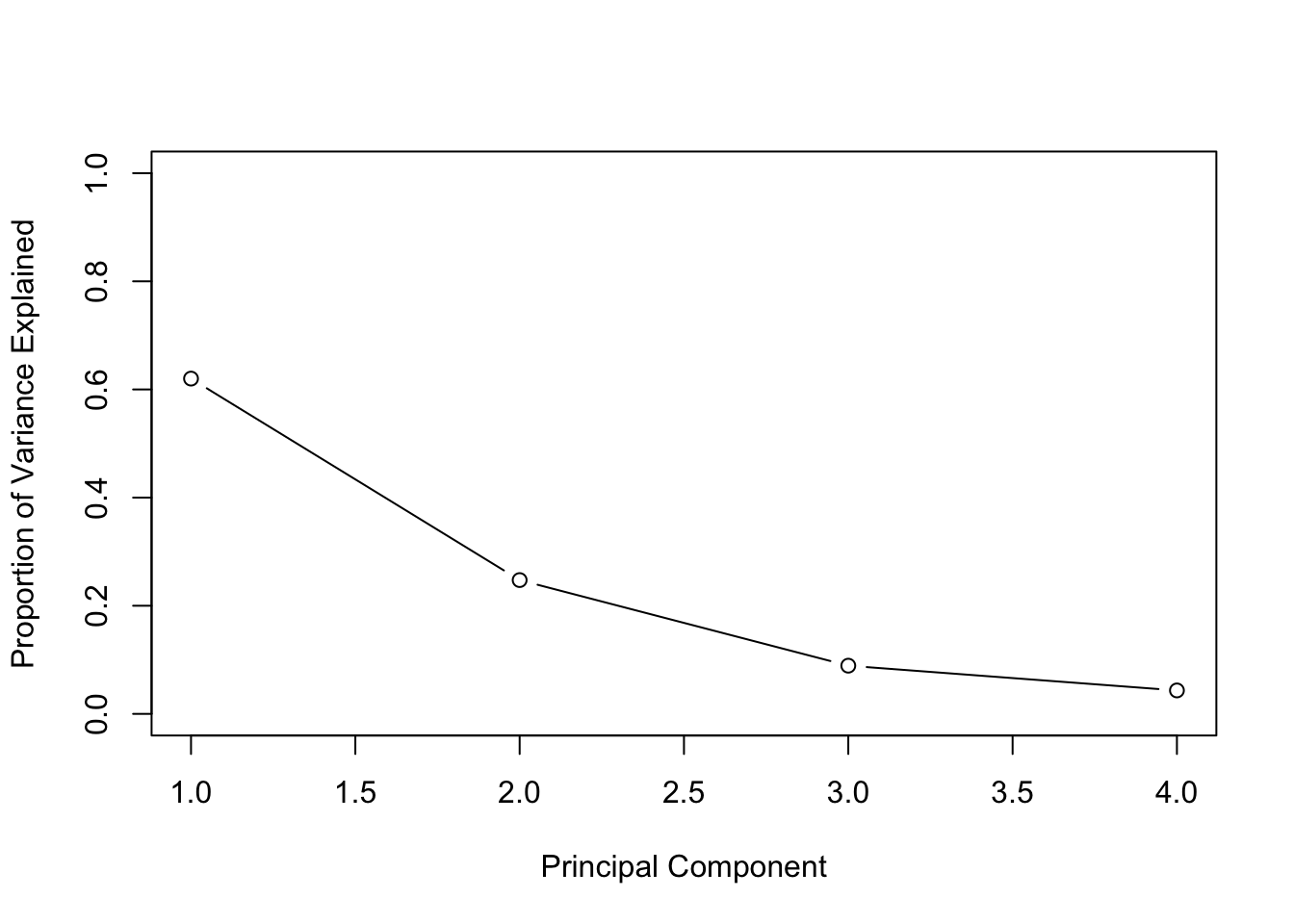
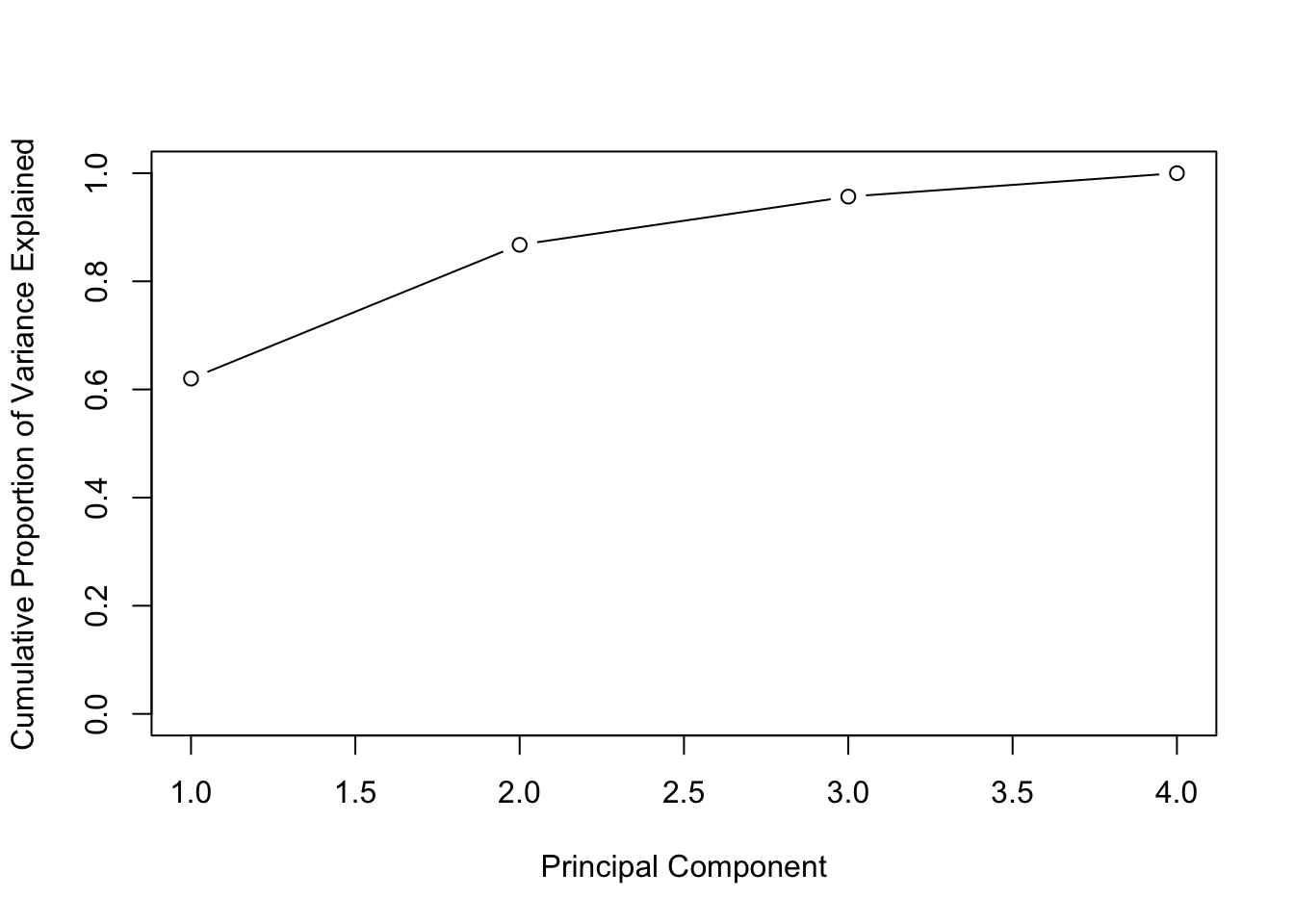
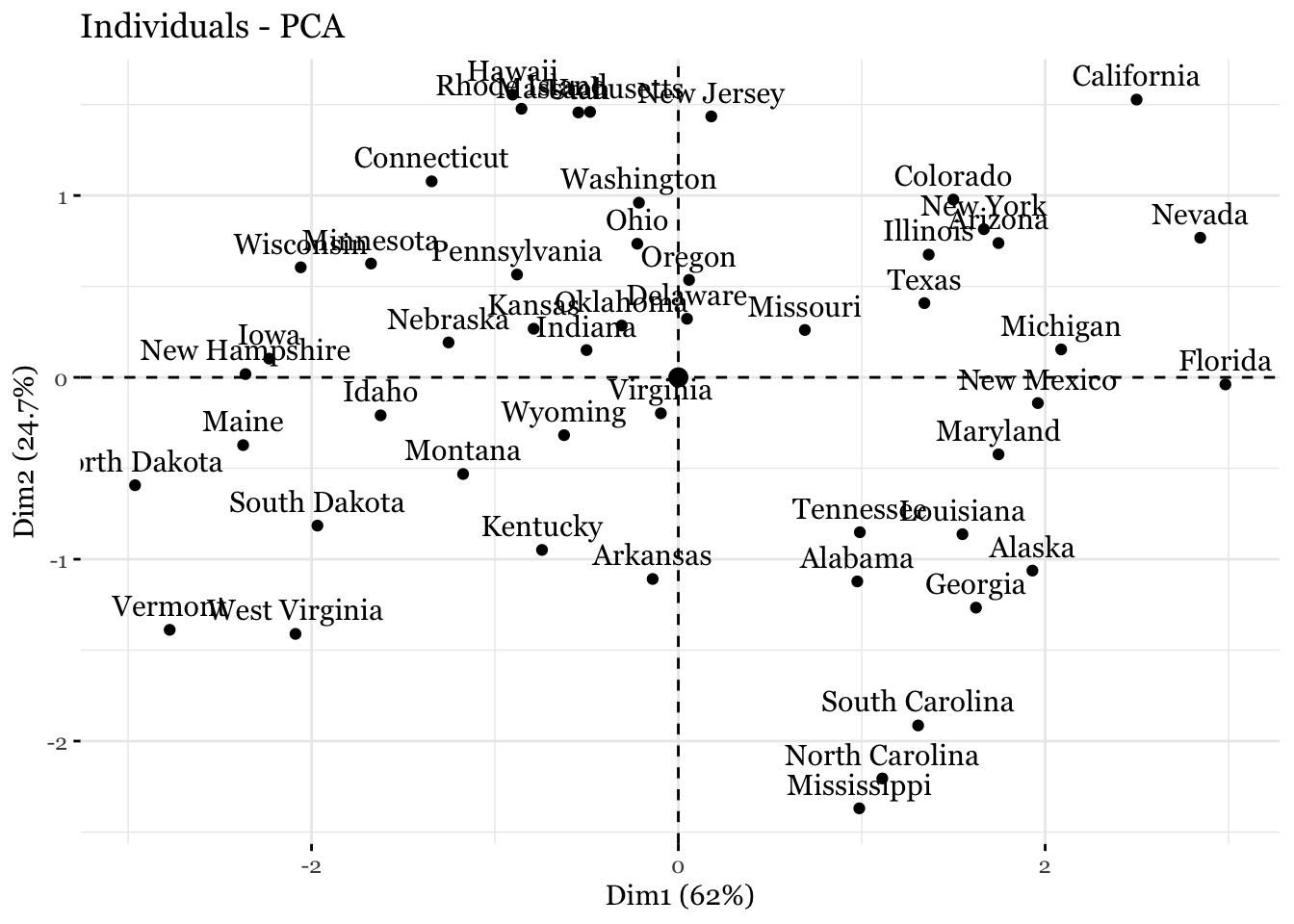
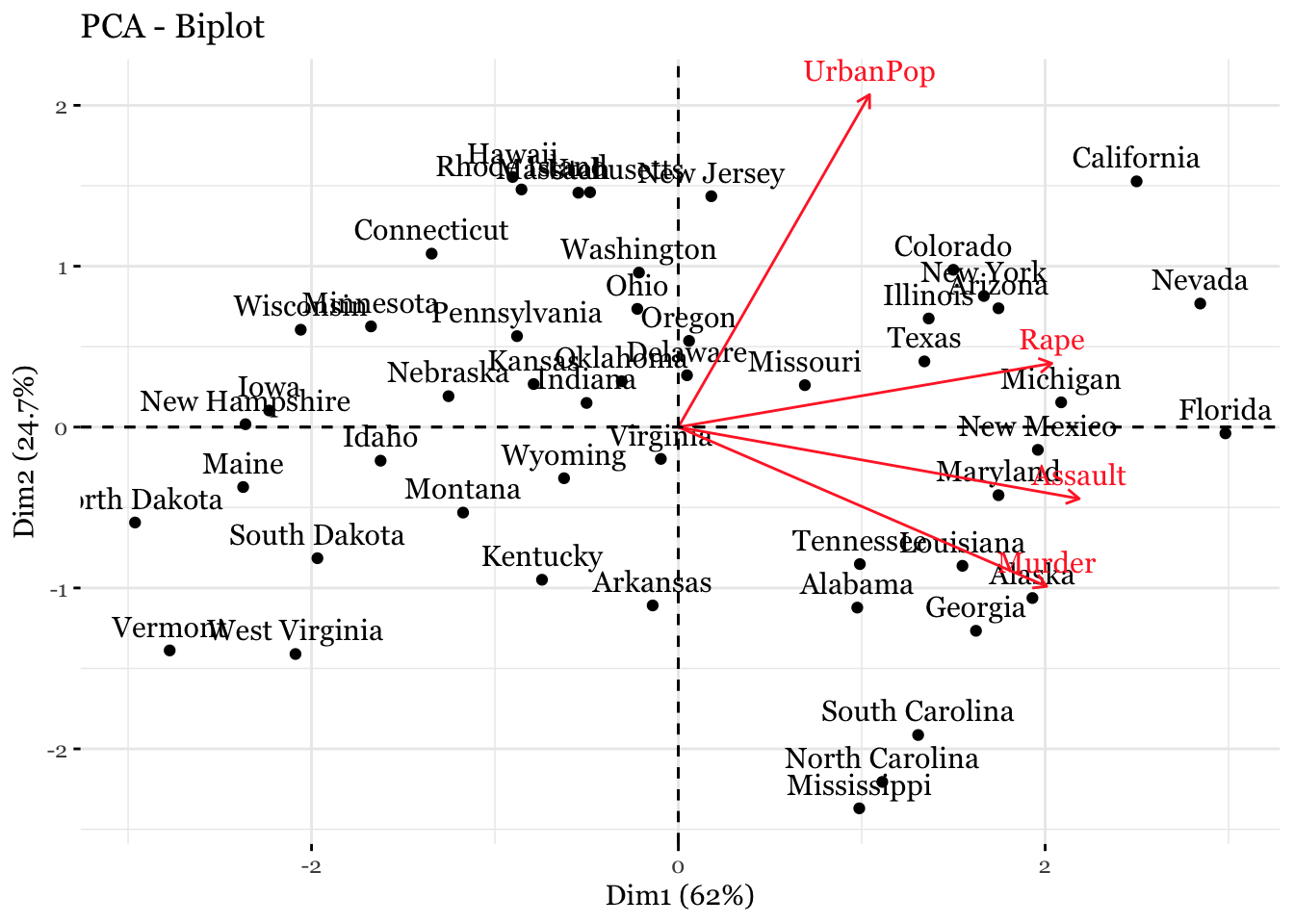
## Gentle Machine Learning## Principal Component Analysis# Dataset: USArrests is the sample dataset used in # McNeil, D. R. (1977) Interactive Data Analysis. New York: Wiley.# Murder numeric Murder arrests (per 100,000)# Assault numeric Assault arrests (per 100,000)# UrbanPop numeric Percent urban population# Rape numeric Rape arrests (per 100,000)# For each of the fifty states in the United States, the dataset contains the number # of arrests per 100,000 residents for each of three crimes: Assault, Murder, and Rape. # UrbanPop is the percent of the population in each state living in urban areas.library(datasets)library(ISLR)arrest = USArrestsstates=row.names(USArrests)names(USArrests)
[1] "Murder" "Assault" "UrbanPop" "Rape"
# Get means and variances of variablesapply(USArrests, 2, mean)
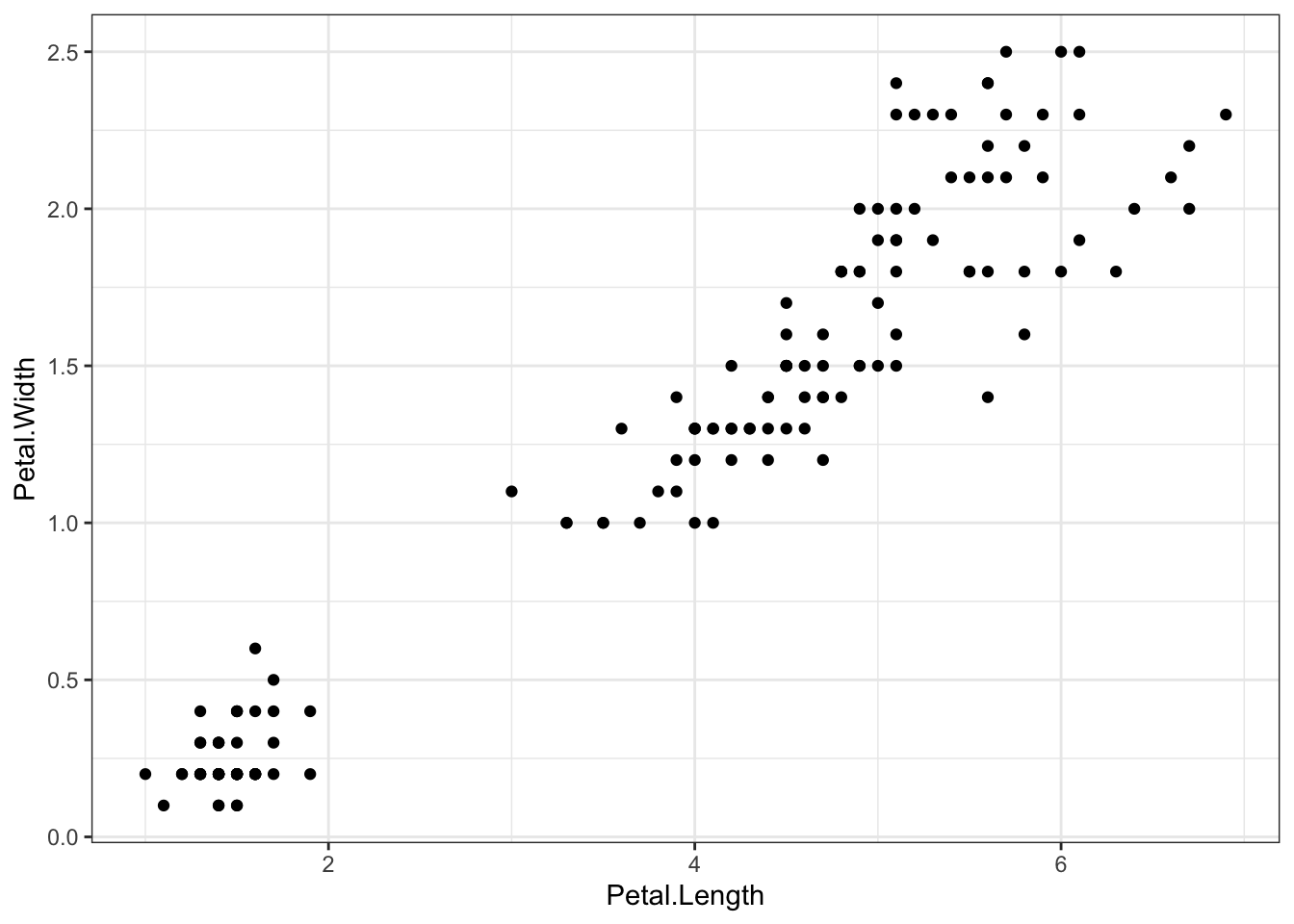
## Iris example# Without grouping by speciesggplot(iris, aes(Petal.Length, Petal.Width)) +geom_point() +theme_bw() +scale_color_manual(values=c("firebrick1","forestgreen","darkblue"))
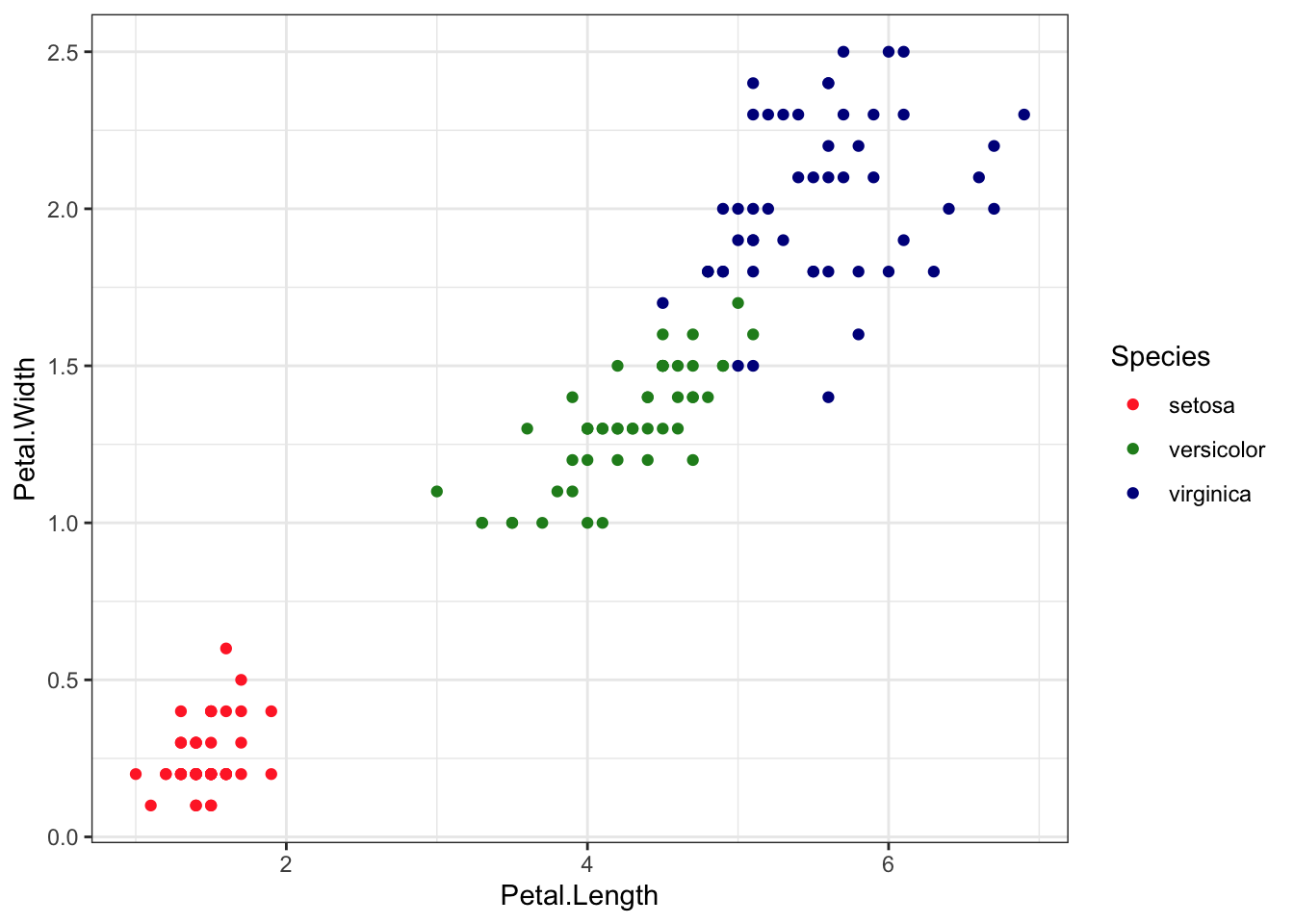
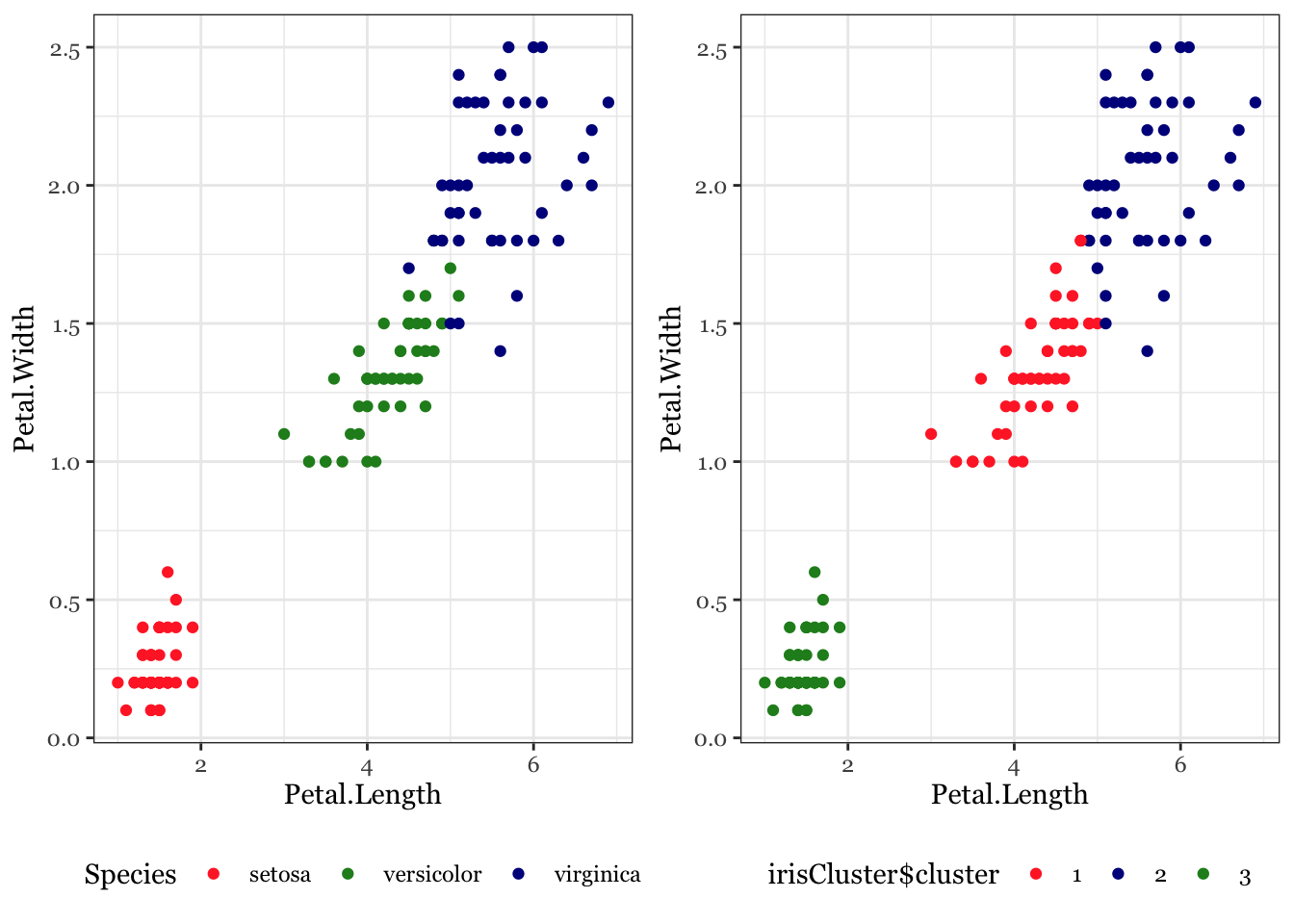
# With grouping by speciesggplot(iris, aes(Petal.Length, Petal.Width, color = Species)) +geom_point() +theme_bw() +scale_color_manual(values=c("firebrick1","forestgreen","darkblue"))
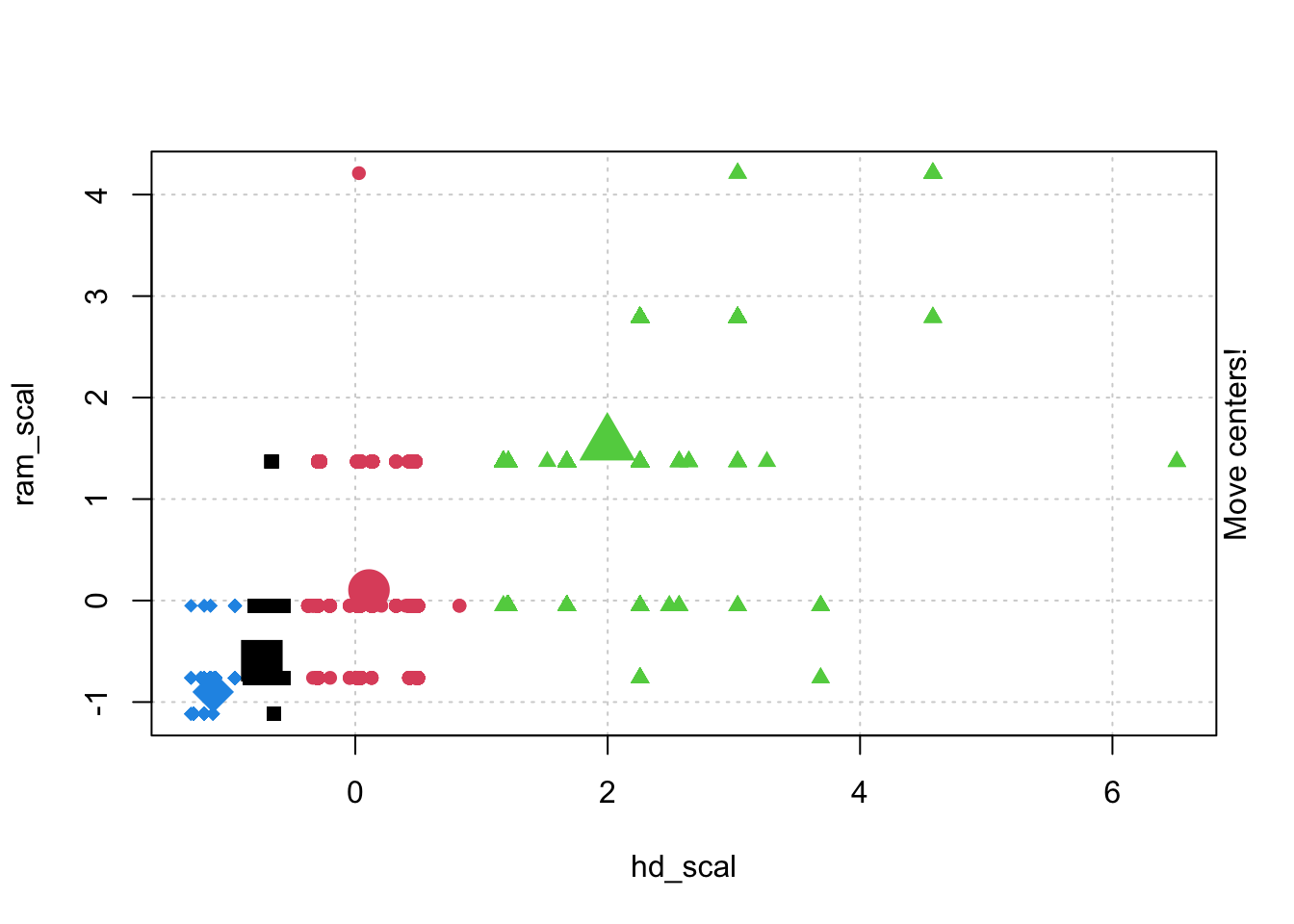
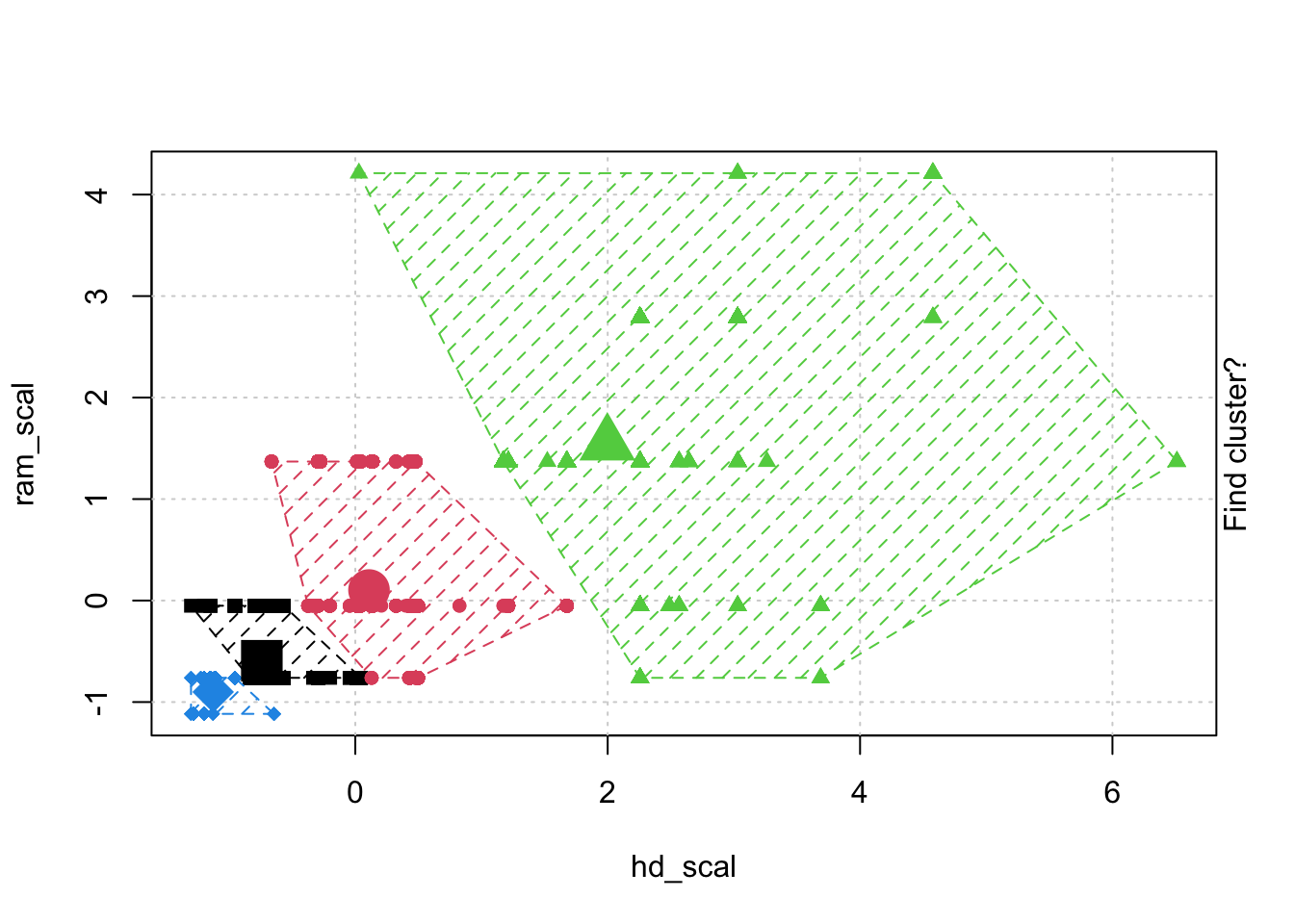
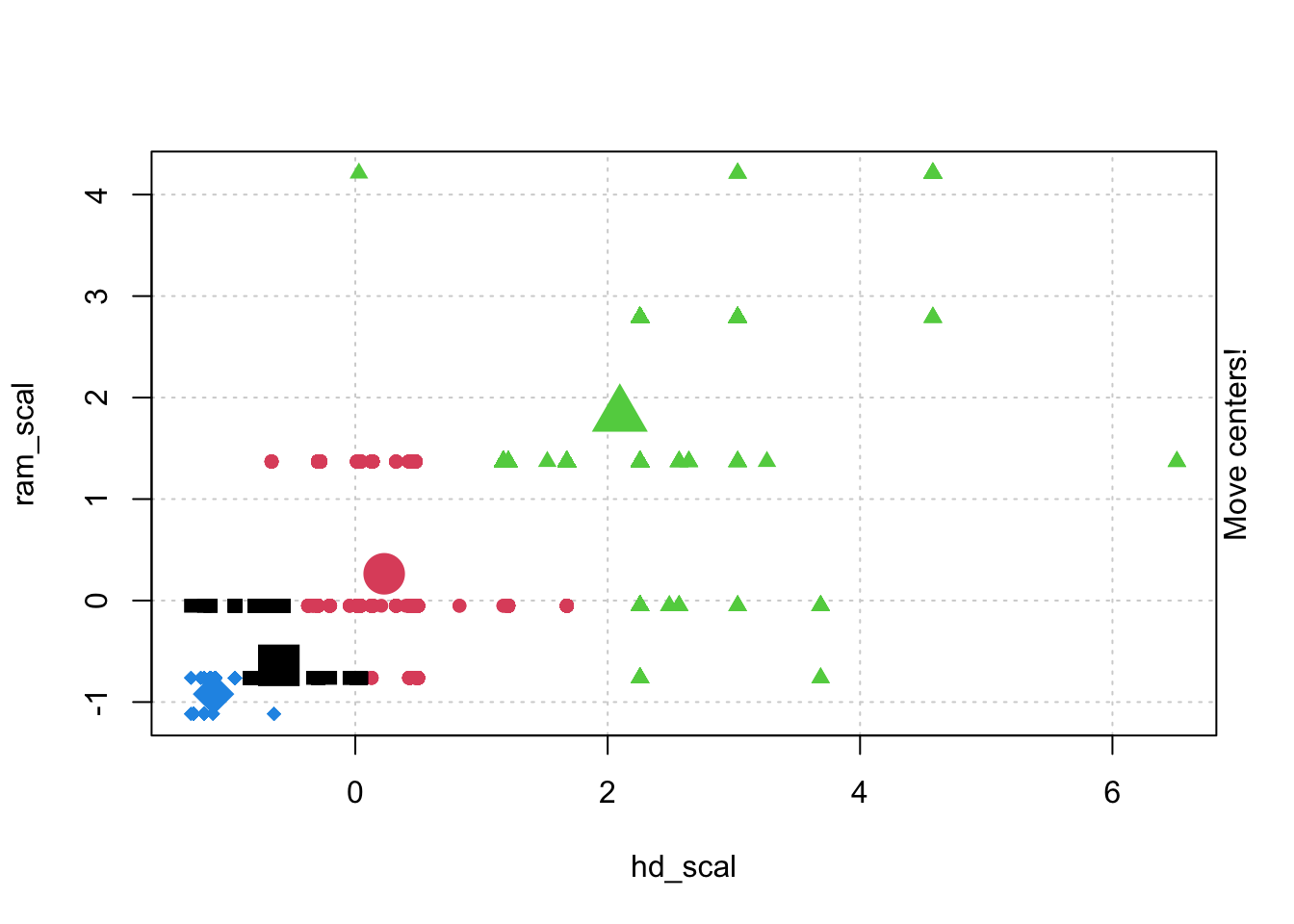
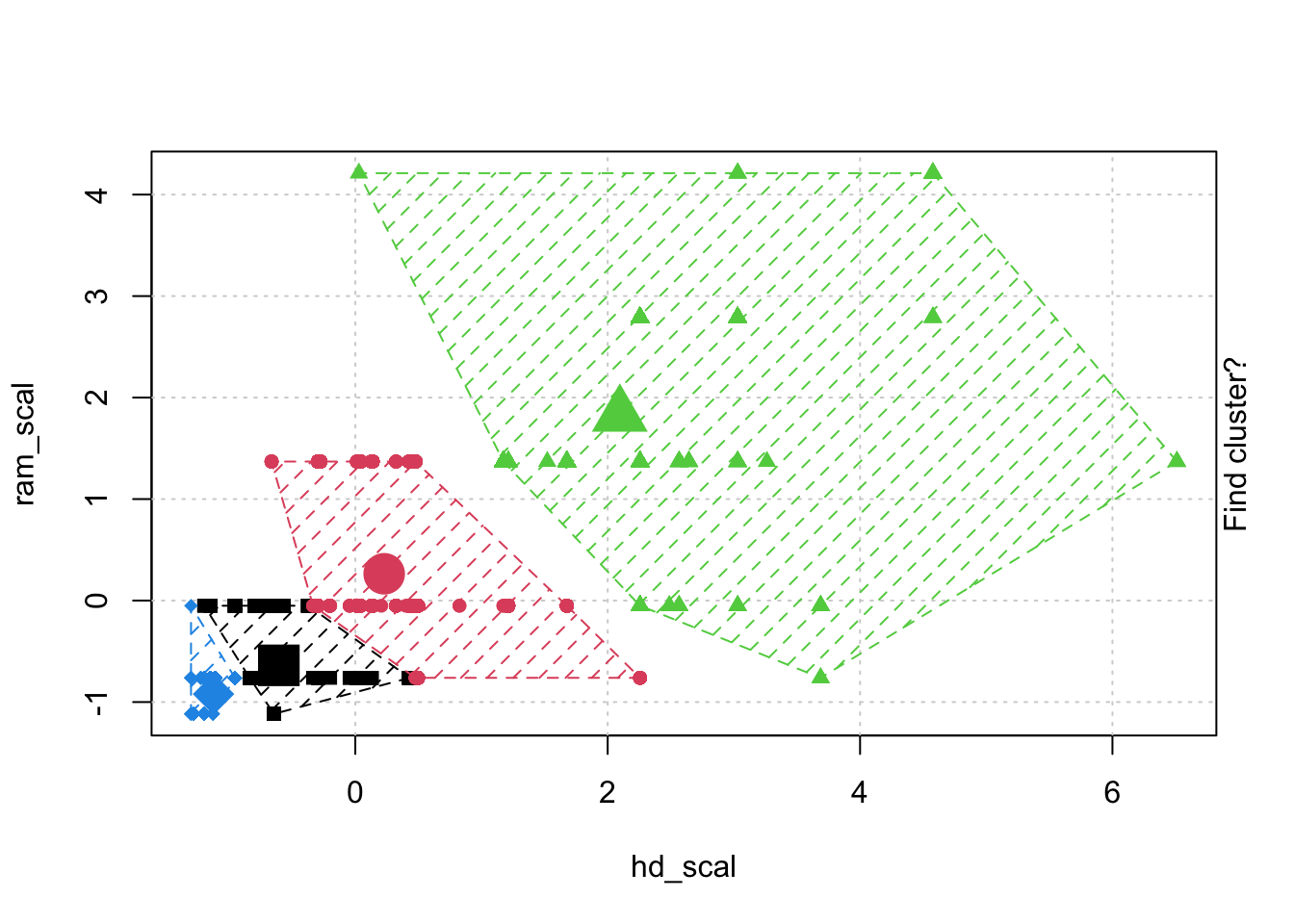
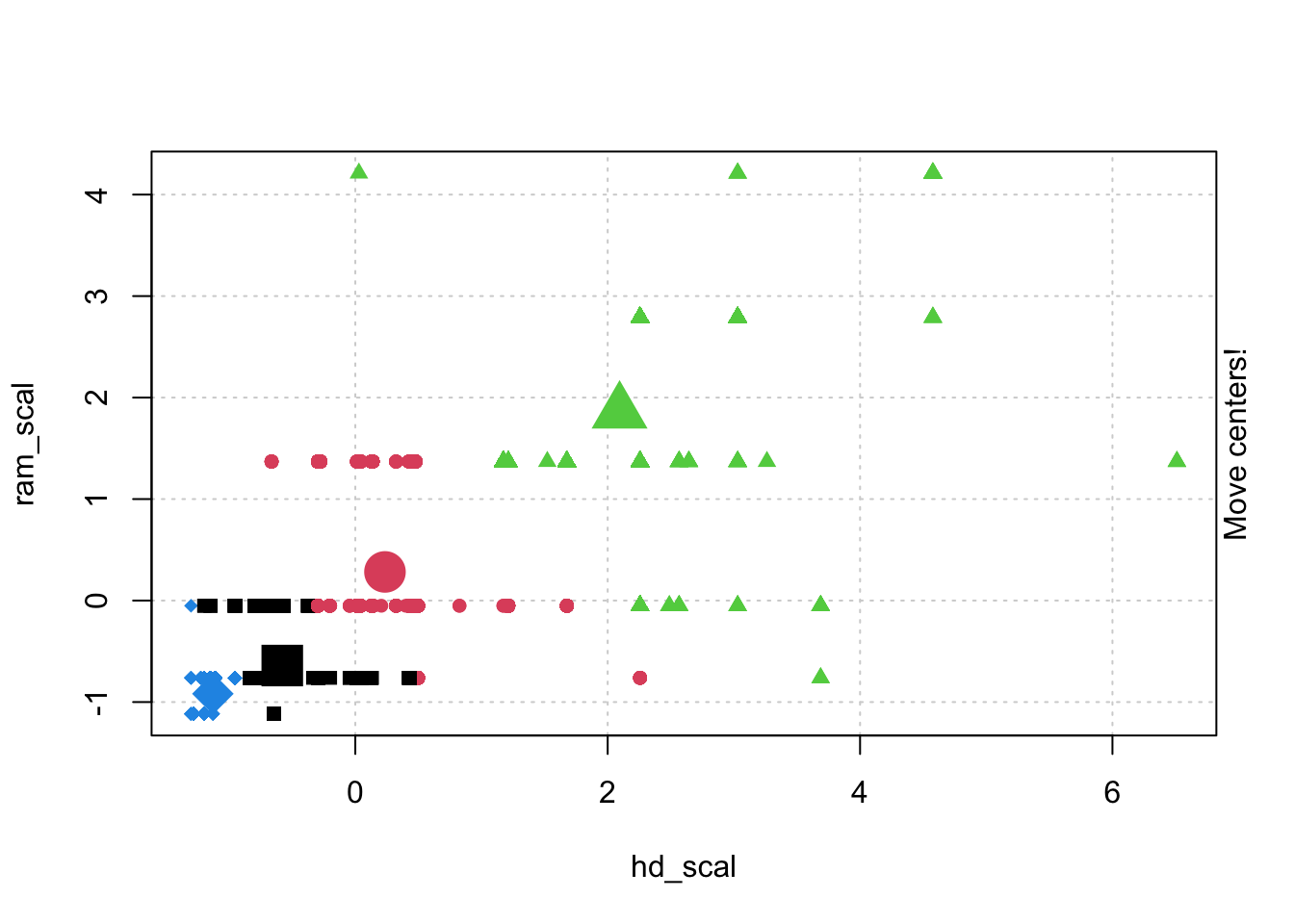
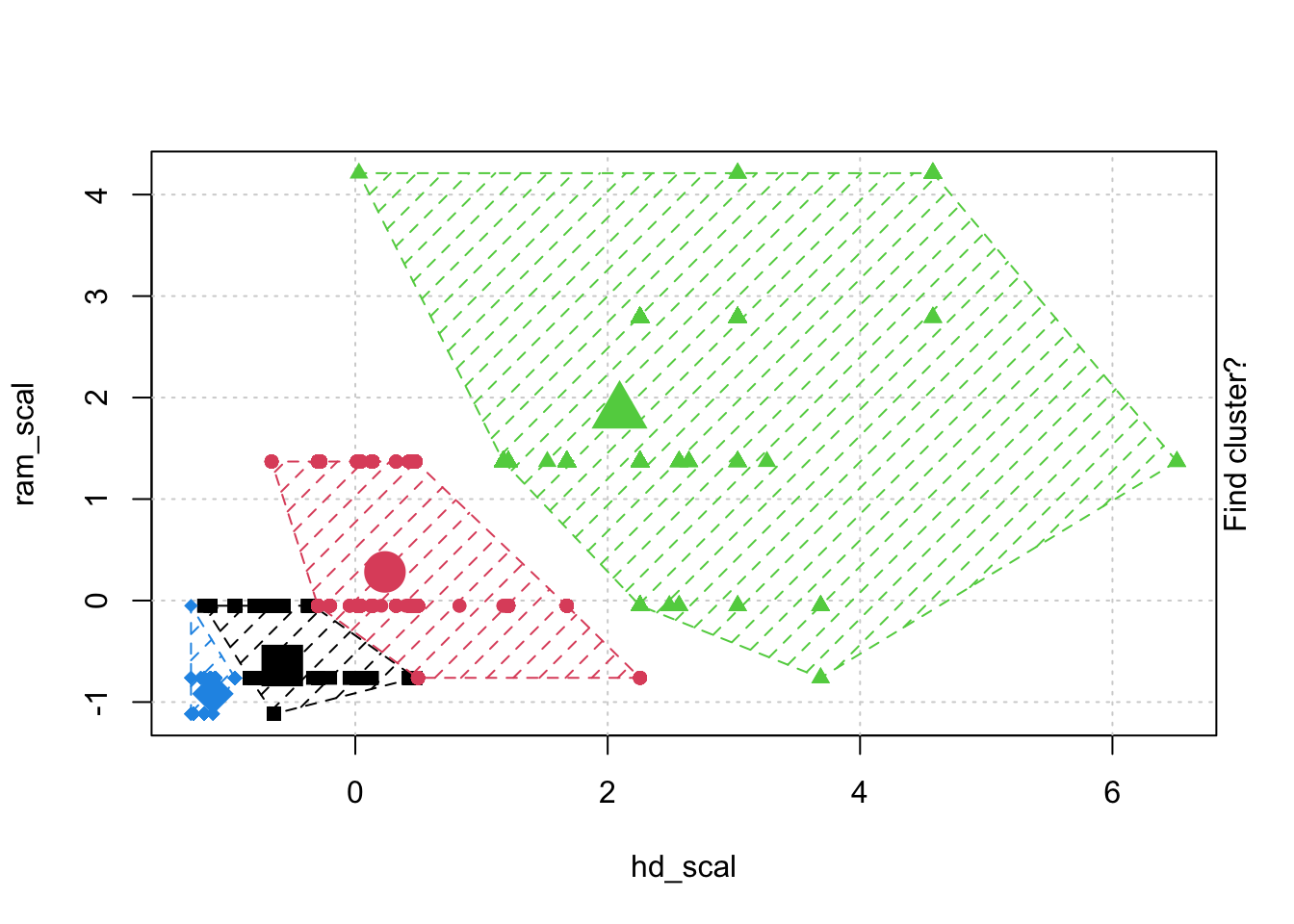
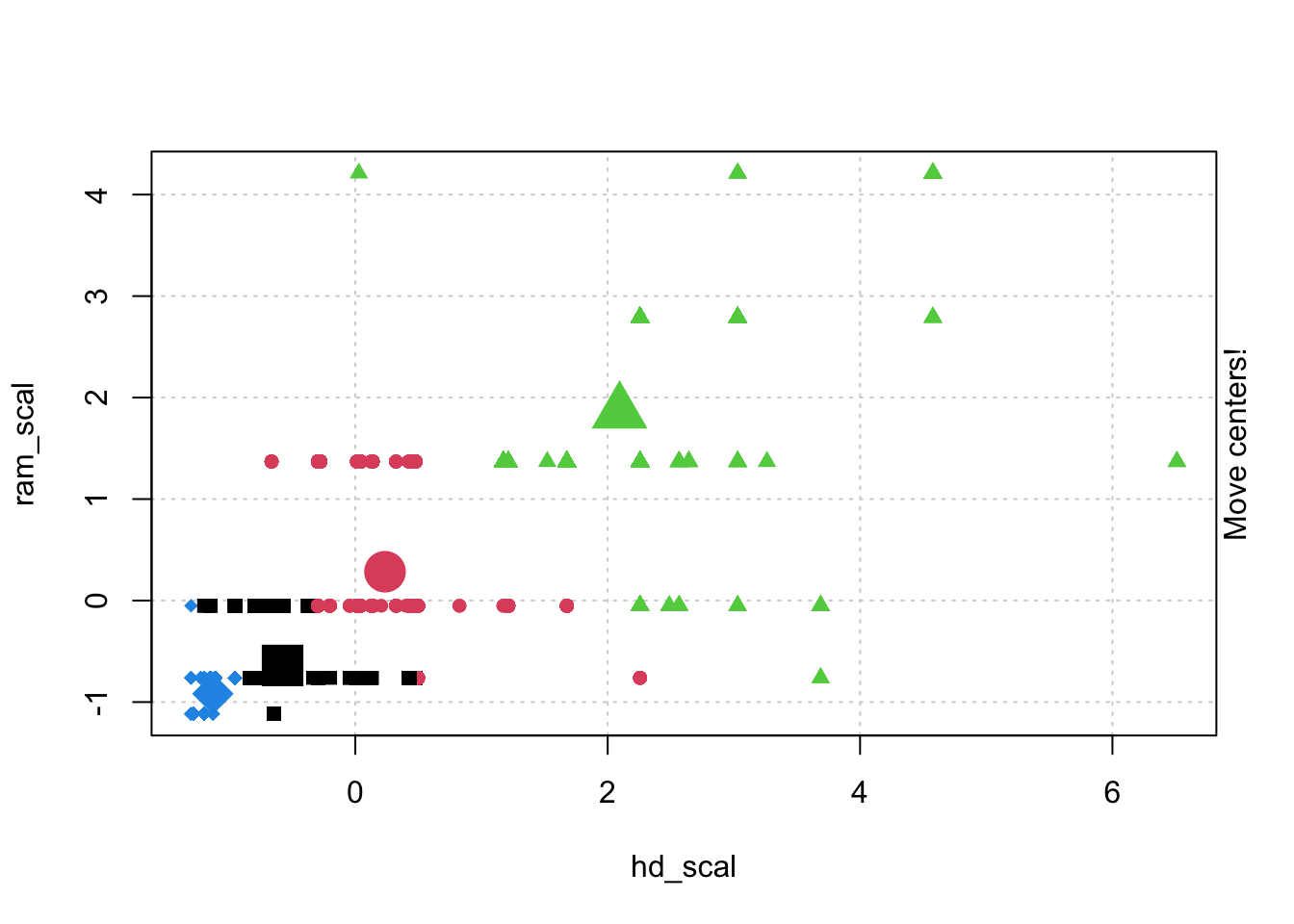
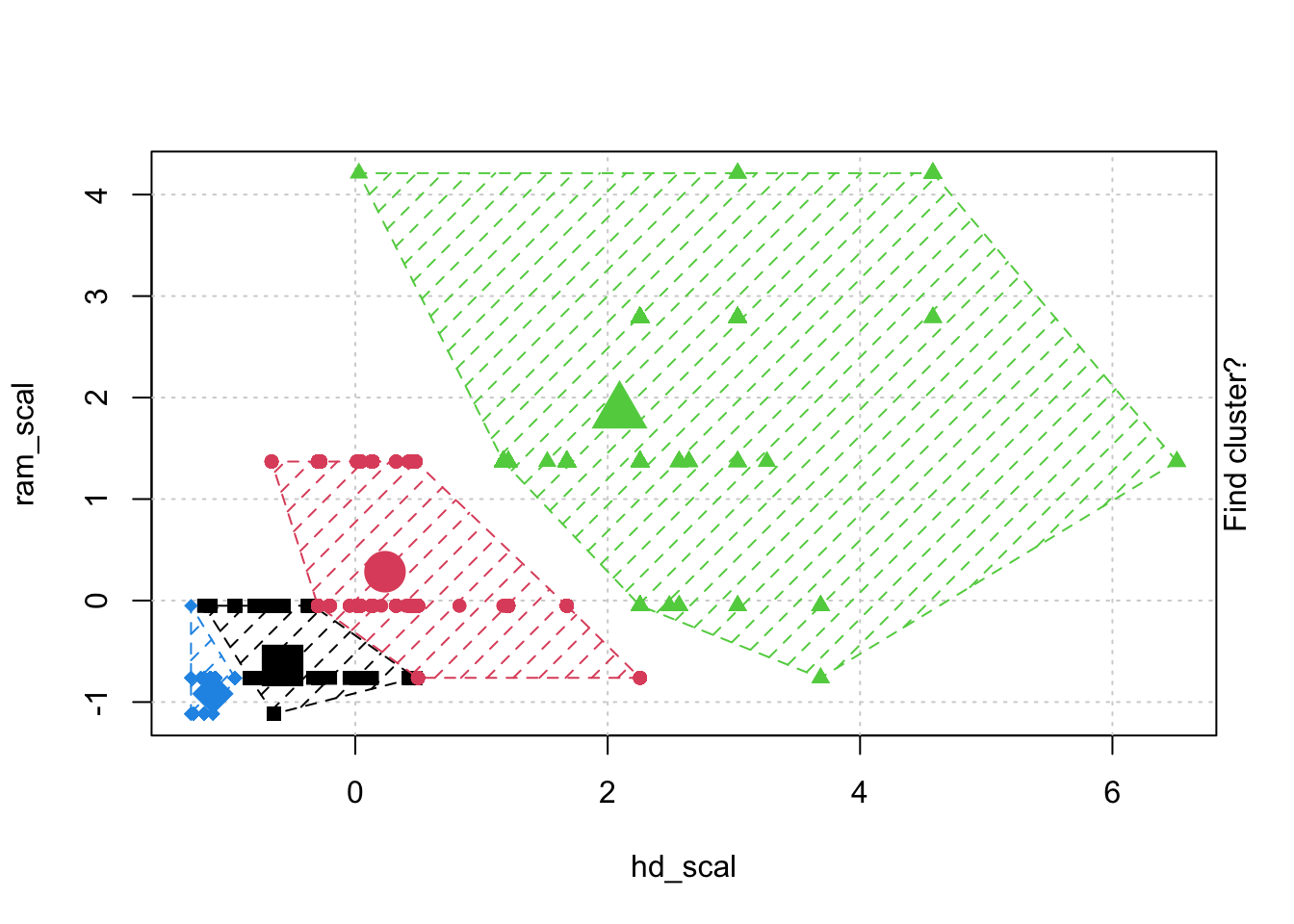
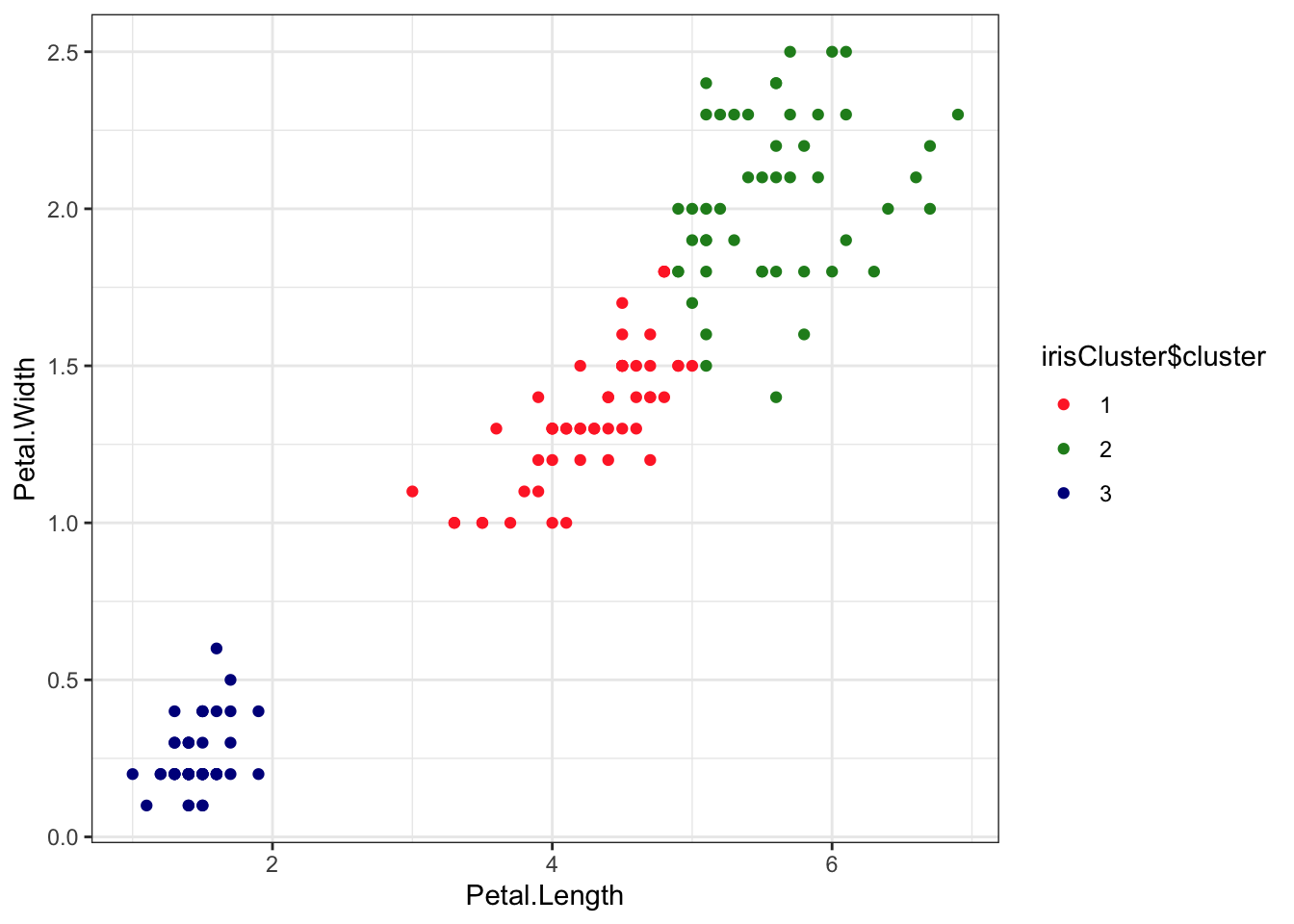
# Check k-means clusters## Starting with three clusters and 20 initial configurationsset.seed(20)irisCluster <-kmeans(iris[, 3:4], 3, nstart =20)irisCluster
## Wine example# The wine dataset contains the results of a chemical analysis of wines # grown in a specific area of Italy. Three types of wine are represented in the # 178 samples, with the results of 13 chemical analyses recorded for each sample. # Variables used in this example:# Alcohol# Malic: Malic acid# Ash# Source: http://archive.ics.uci.edu/ml/datasets/Wine# Import wine datasetlibrary(readr)wine <-read_csv("https://raw.githubusercontent.com/datageneration/gentlemachinelearning/master/data/wine.csv")
Rows: 178 Columns: 14
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (14): class, Alcohol, Malic, Ash, Ash_alcalinity, Magnesium, Total_pheno...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
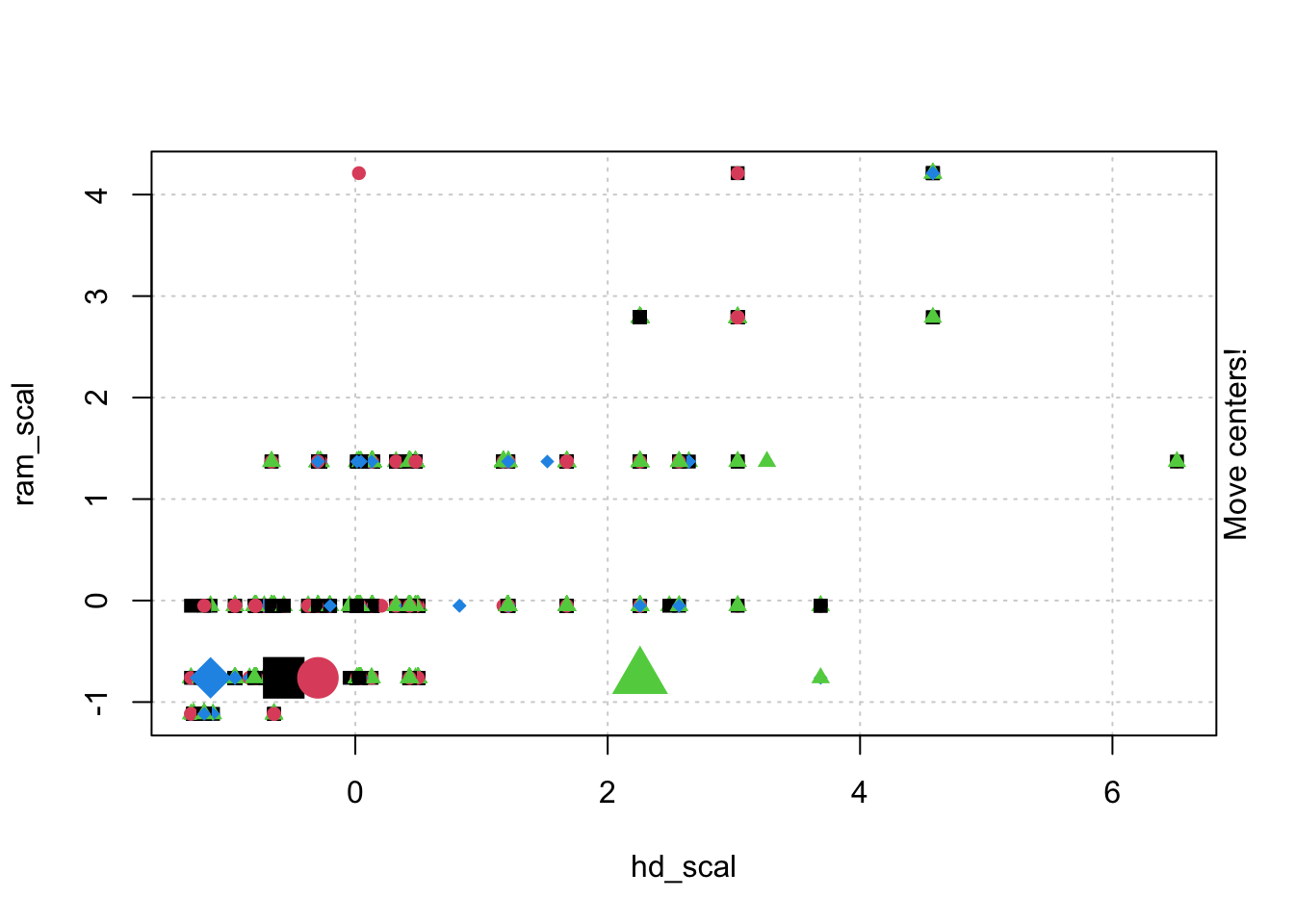
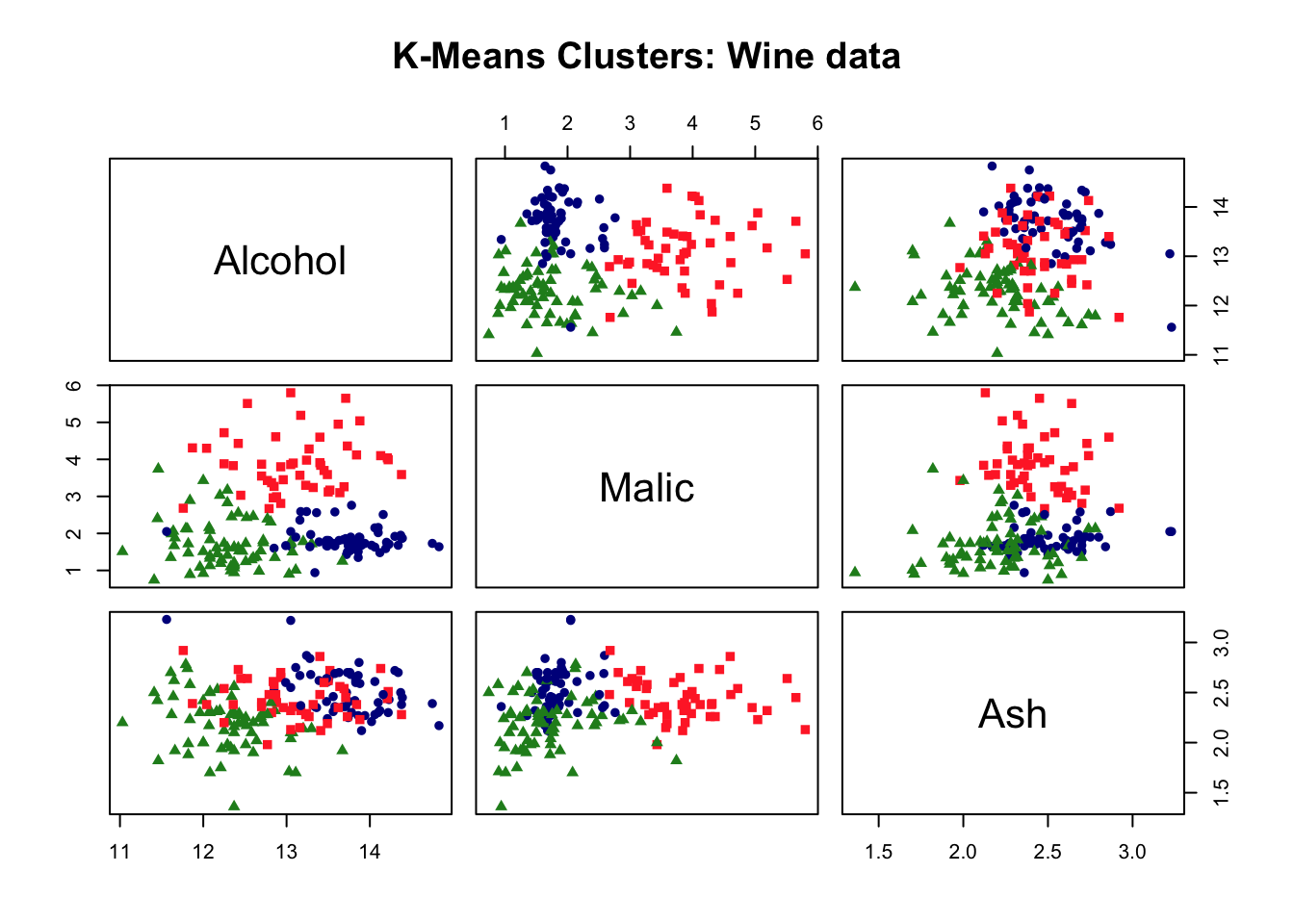
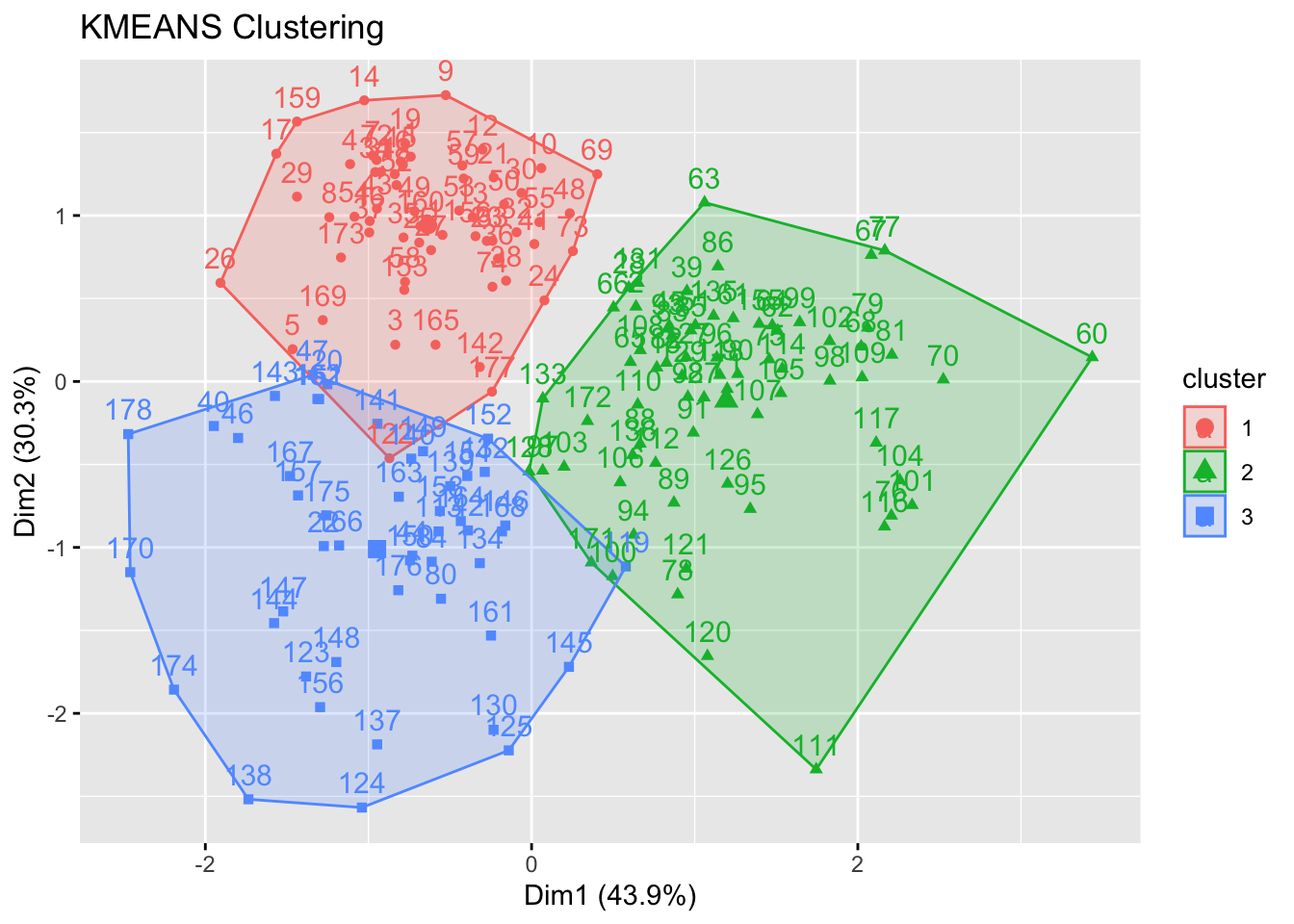
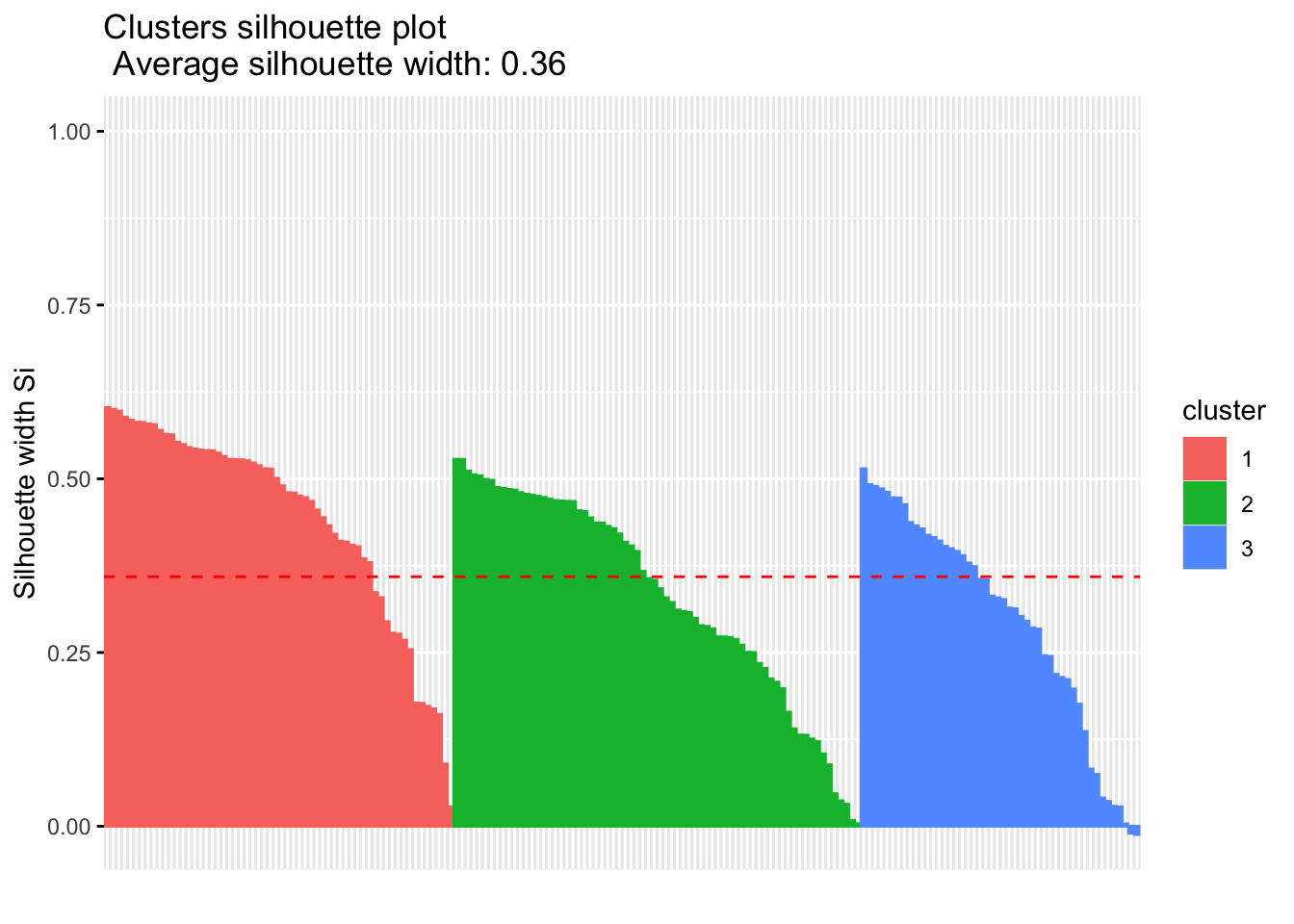
## Choose and scale variableswine_subset <-scale(wine[ , c(2:4)])## Create cluster using k-means, k = 3, with 25 initial configurationswine_cluster <-kmeans(wine_subset, centers =3,iter.max =10,nstart =25)wine_cluster
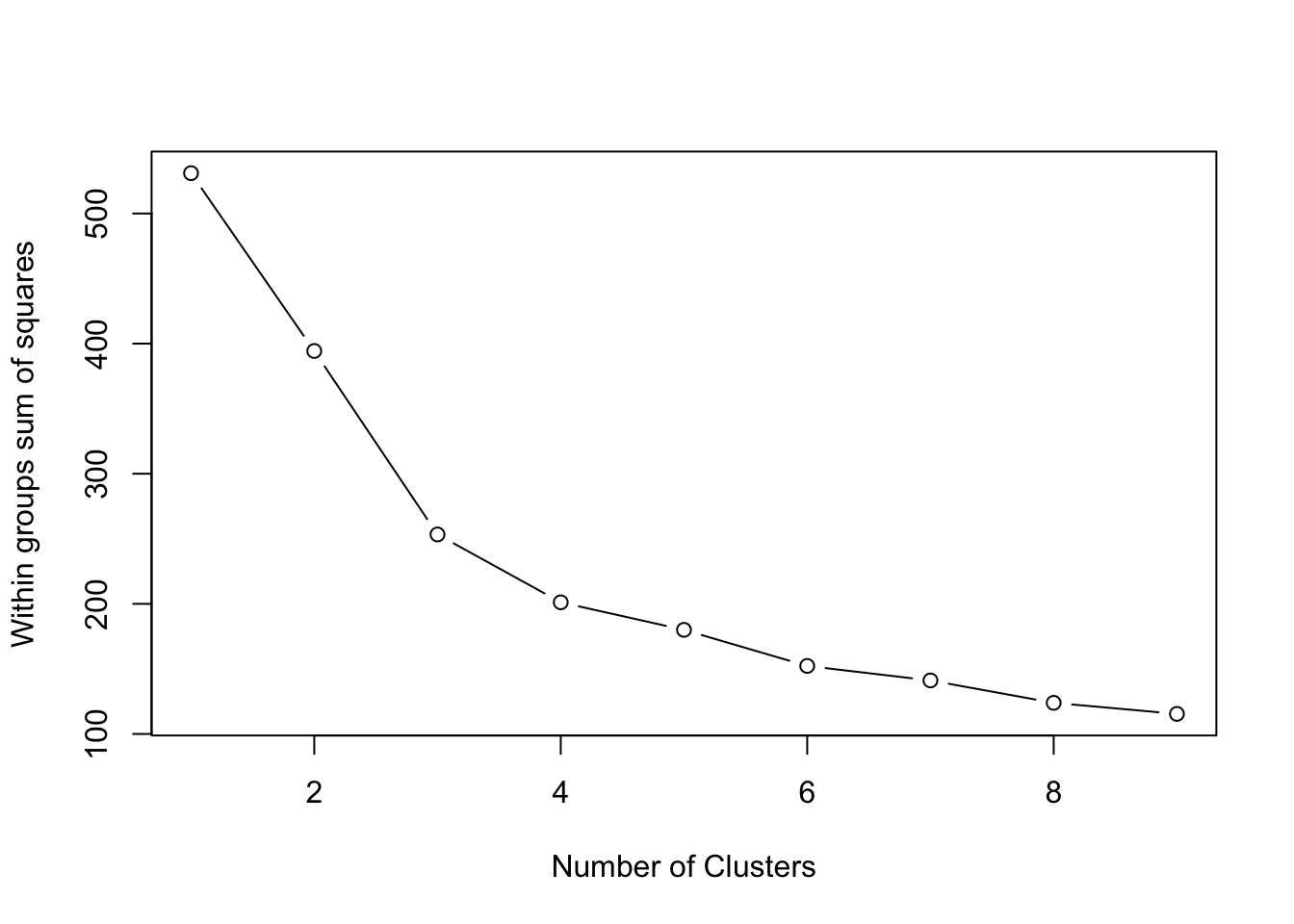
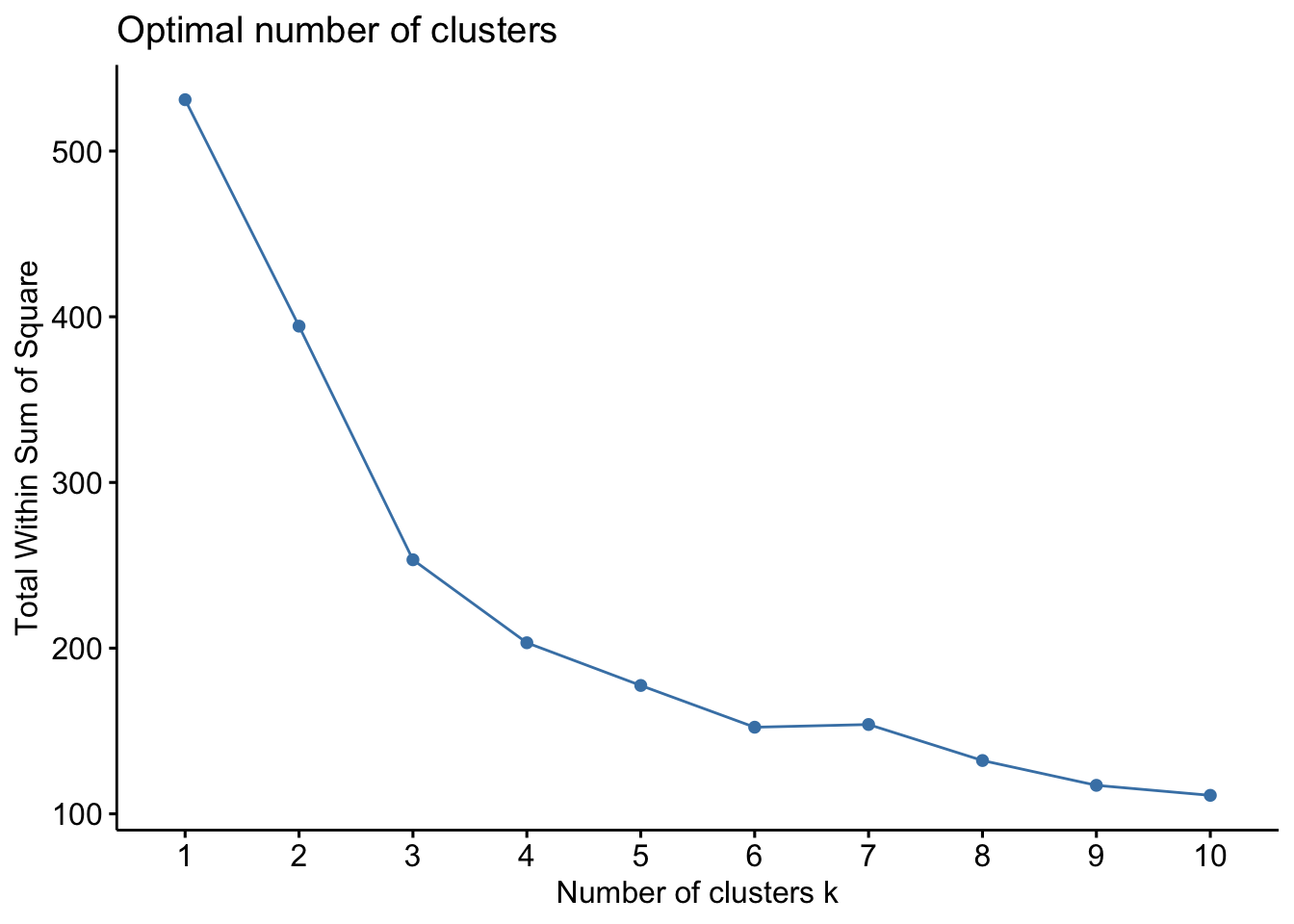
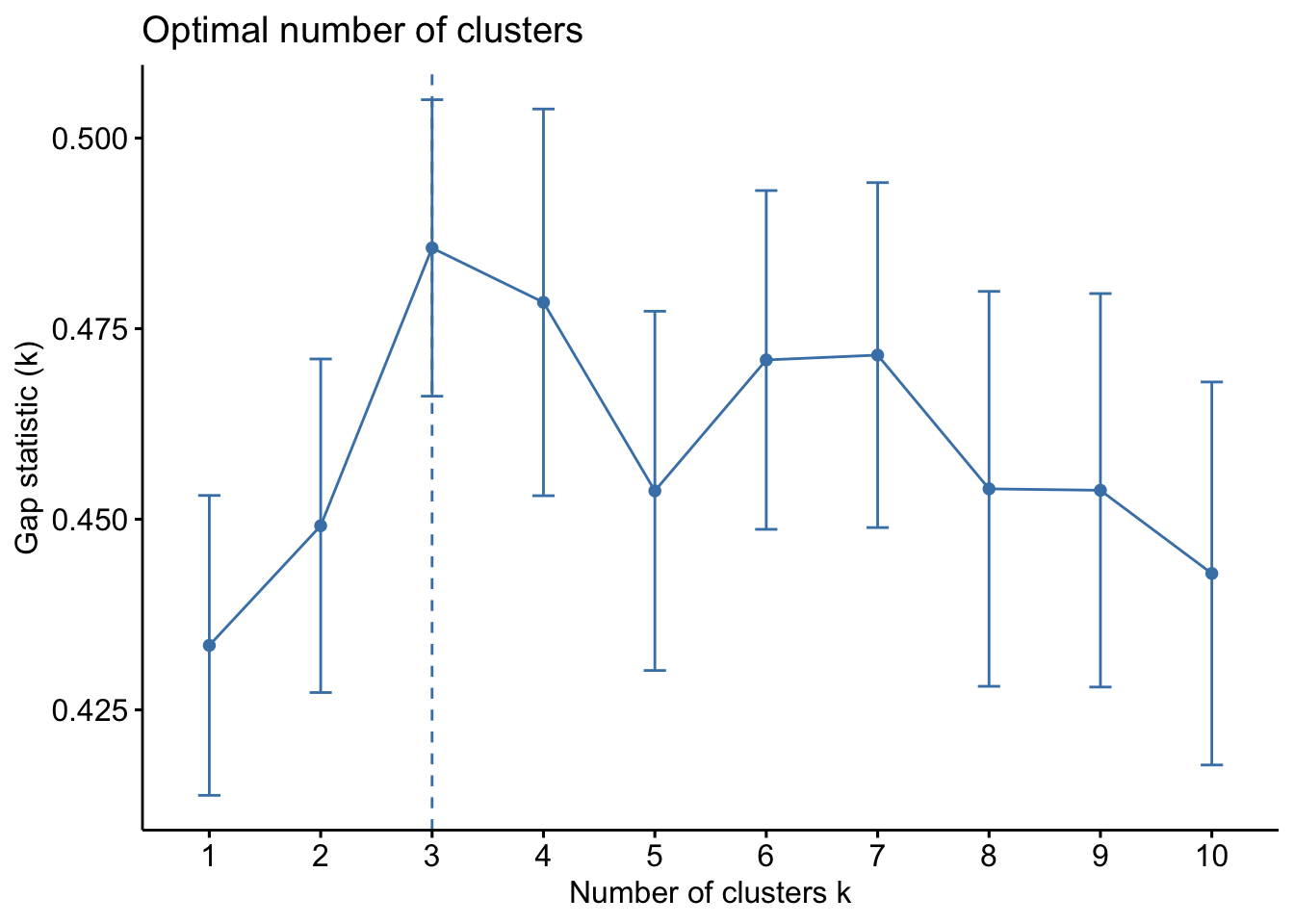
# Create a function to compute and plot total within-cluster sum of square (within-ness)wssplot <-function(data, nc=15, seed=1234){ wss <- (nrow(data)-1)*sum(apply(data,2,var))for (i in2:nc){set.seed(seed) wss[i] <-sum(kmeans(data, centers=i)$withinss)}plot(1:nc, wss, type="b", xlab="Number of Clusters",ylab="Within groups sum of squares")}# plotting values for each cluster starting from 1 to 9wssplot(wine_subset, nc =9)
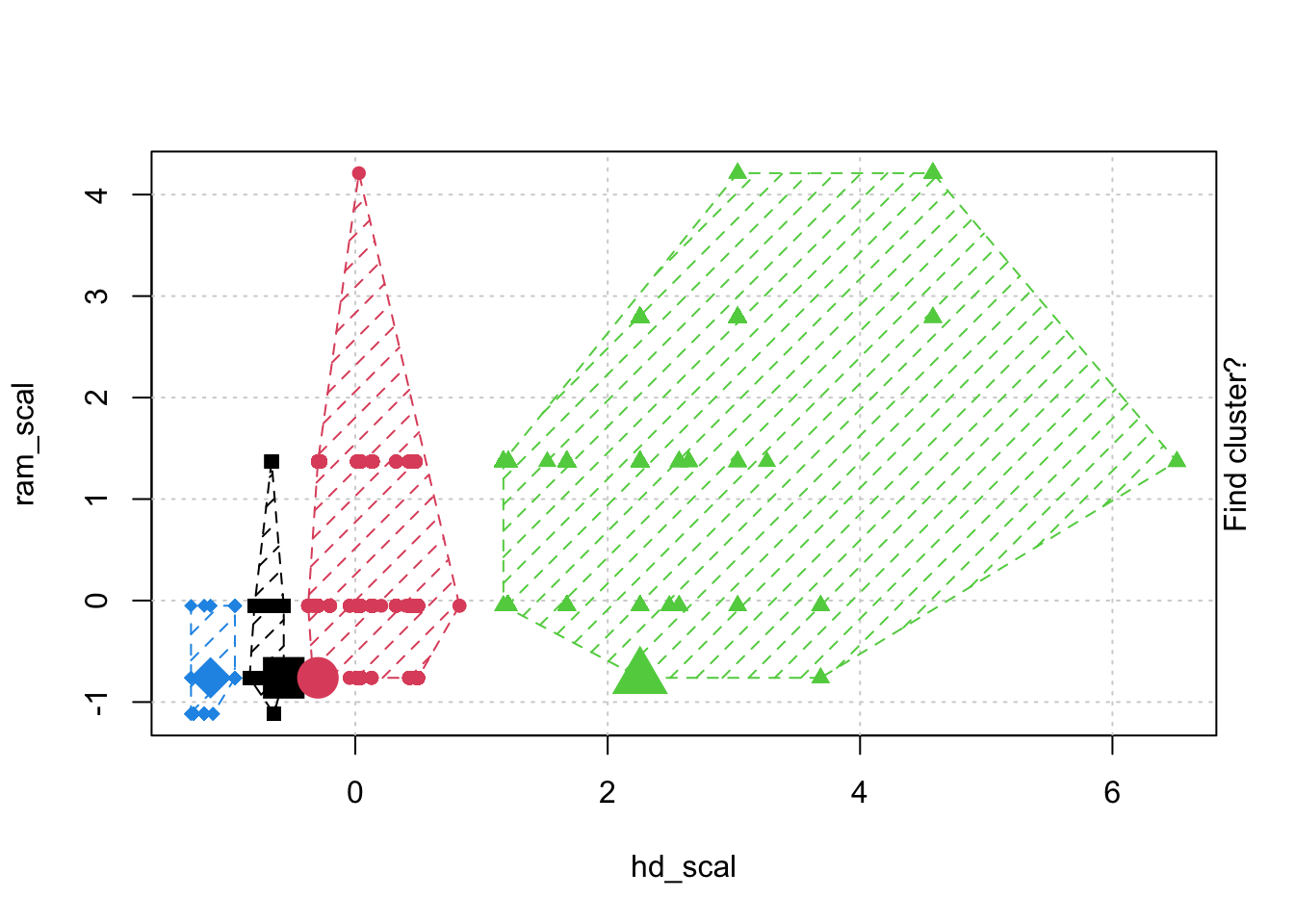
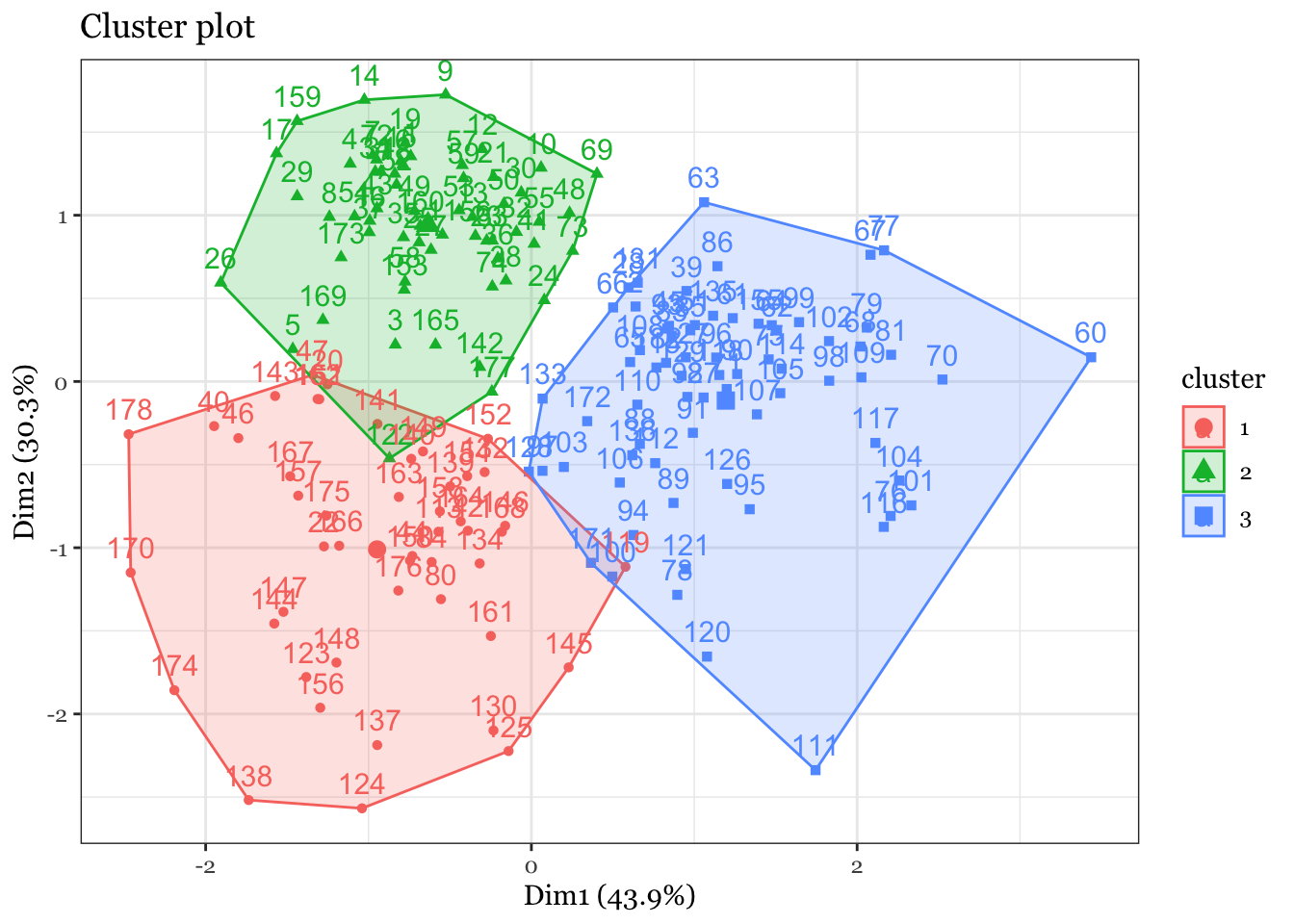
fviz_cluster(wine_cluster, data = wine_subset) +theme_bw() +theme(text =element_text(family="Georgia"))
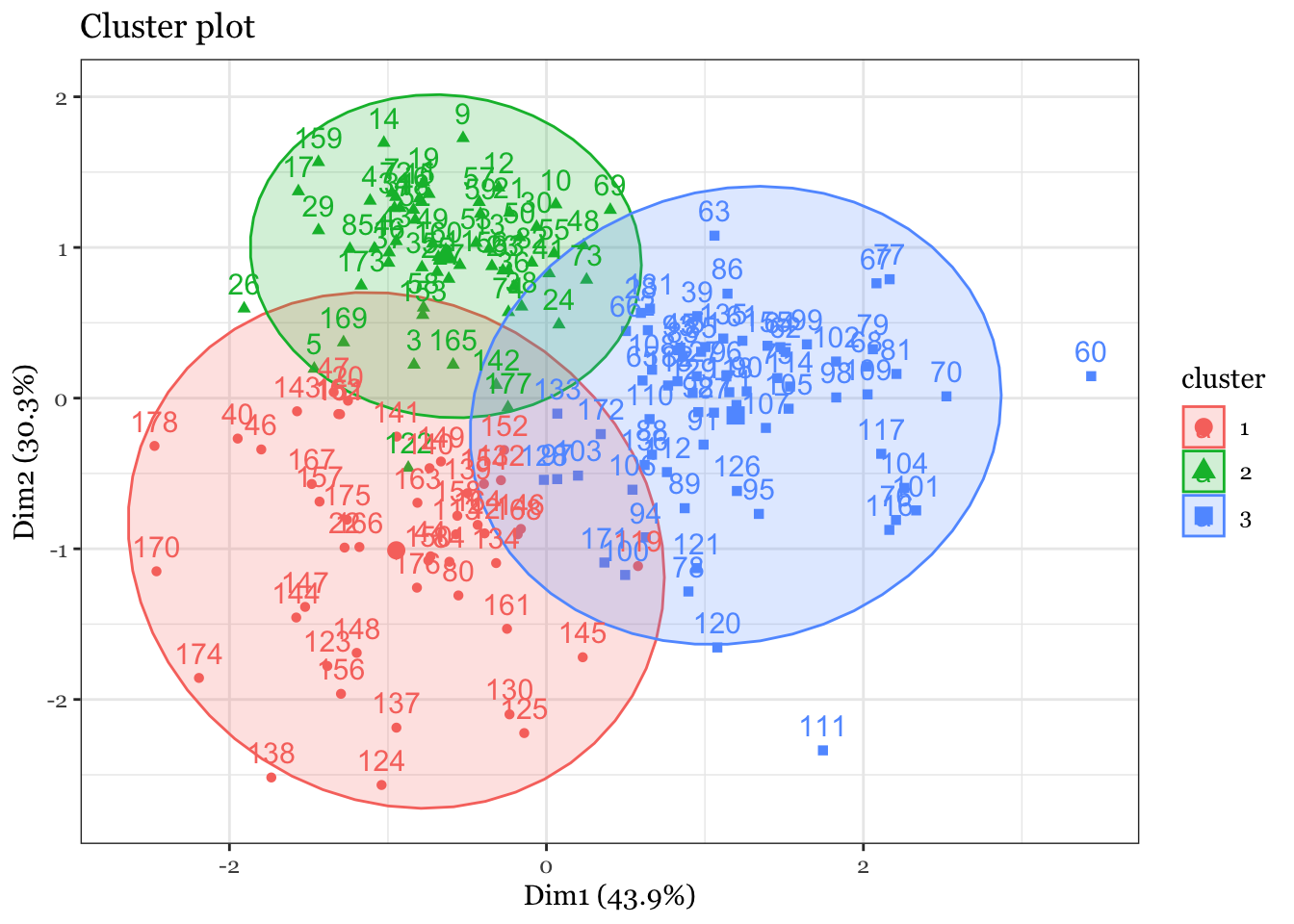
fviz_cluster(wine_cluster, data = wine_subset, ellipse.type ="norm") +theme_bw() +theme(text =element_text(family="Georgia"))
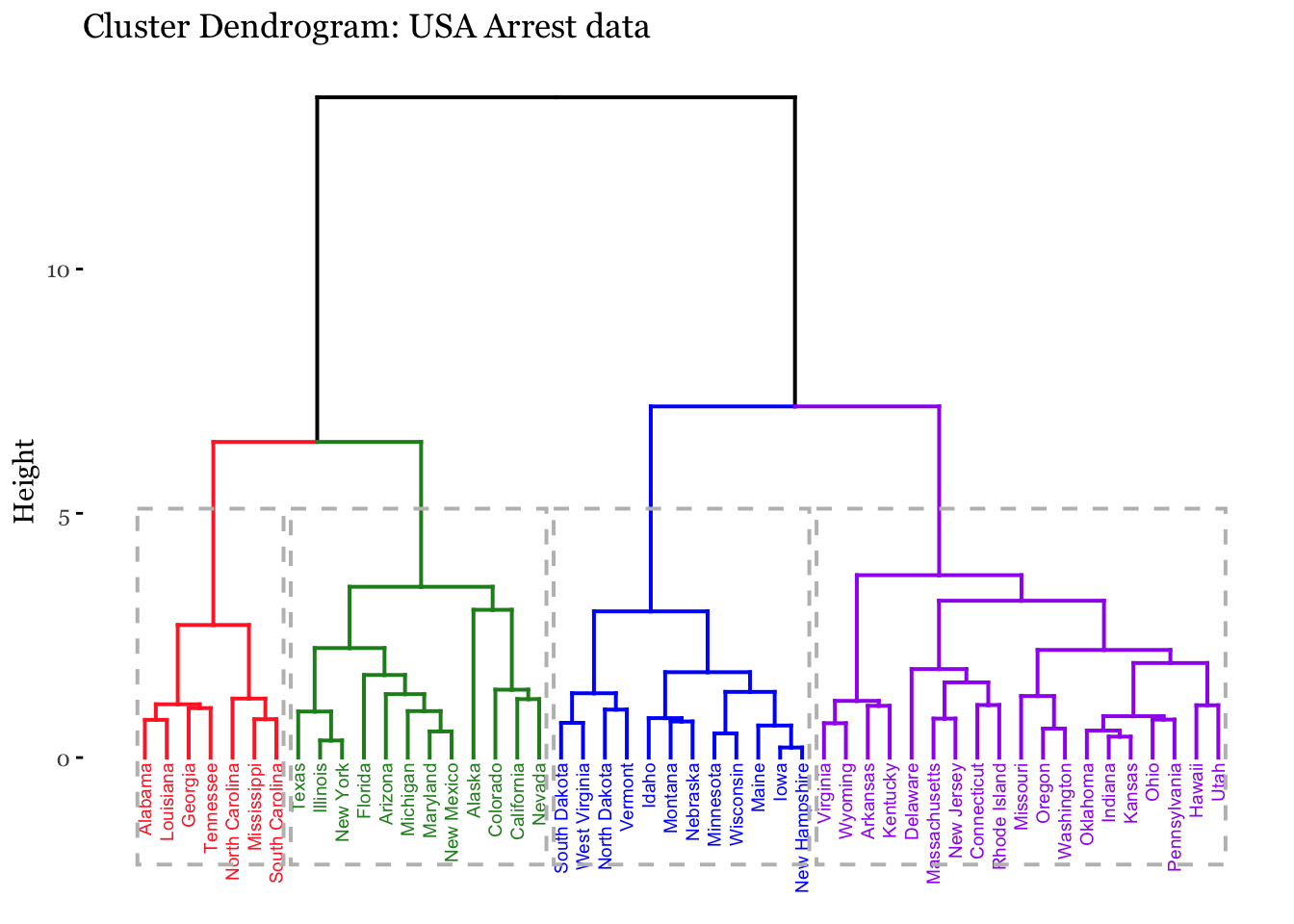
## Hierarchical Clustering## Dataset: USArrests# install.packages("cluster")arrest.hc <- USArrests %>%scale() %>%# Scale all variablesdist(method ="euclidean") %>%# Euclidean distance for dissimilarity hclust(method ="ward.D2") # Compute hierarchical clustering# Generate dendrogram using factoextra packagefviz_dend(arrest.hc, k =4, # Four groupscex =0.5, k_colors =c("firebrick1","forestgreen","blue", "purple"),color_labels_by_k =TRUE, # color labels by groupsrect =TRUE, # Add rectangle (cluster) around groups,main ="Cluster Dendrogram: USA Arrest data") +theme(text =element_text(family="Georgia"))
Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
of ggplot2 3.3.4.
ℹ The deprecated feature was likely used in the factoextra package.
Please report the issue at <https://github.com/kassambara/factoextra/issues>.